







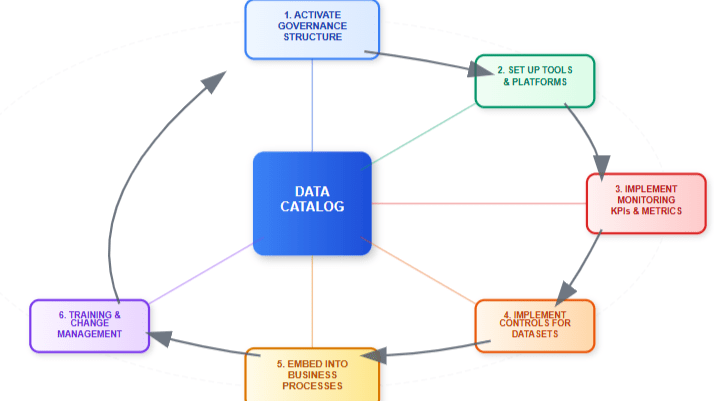
A centralized metadata strategy is the backbone of robust, scalable data governance. Organizations wrestle with proliferating data sources, disparate glossaries, inconsistent lineage, and fragmented access controls. When metadata lives in many places and formats, governance becomes reactive and brittle. Centralizing metadata eliminates duplication of effort, reduces ambiguity, and creates a single reference point for policy enforcement, discovery, and compliance. A thoughtful strategy treats metadata as a managed product, aligning people, processes, and technology so the enterprise can scale governance without sacrificing agility.
The case for centralization
Centralized metadata consolidates descriptive, structural, and operational information about data assets into a cohesive fabric. This consolidation addresses three persistent problems: discoverability, trust, and compliance. Discoverability improves because cataloging and tagging occur in one system that indexes across sources, making it faster for analysts and product teams to find what they need. Trust increases when business definitions, data quality metrics, and lineage are visible and authoritative. Compliance is easier to demonstrate because access policies, audit trails, and retention rules are managed consistently. A centralized approach transforms metadata from an afterthought into a strategic asset that supports analytics, reporting, and decision-making.
Core components of a centralized approach
A scalable strategy comprises a shared repository, standardized metadata models, automated ingestion, and governance workflows. The shared repository records business glossaries, technical schemas, ownership, and lineage. Standardized models ensure that the same concepts map consistently across databases, data lakes, and APIs. Automated ingestion pipelines capture schema changes, usage statistics, and data quality scores with minimal manual intervention. Governance workflows embed review, approval, and certification steps so that metadata evolves under controlled processes. A practical implementation also integrates role-based access controls and supports federated models where necessary, so local teams retain autonomy while the backbone metadata maintains consistency.
Technology considerations and integration
Choosing technology for centralization requires balancing flexibility with control. The platform should support connectors across cloud storage, warehouses, streaming platforms, and SaaS applications. It must expose APIs for automation and integrate with identity providers for secure authorization. Metadata search should be fast and contextual, combining full-text search with faceted filters and lineage visualization. Machine-learning-assisted tagging and classification can accelerate onboarding of new assets, but human curation remains critical for high-value definitions and business rules. For many enterprises, the synthesis of open standards like DCAT or schema.org with proprietary enhancements yields both interoperability and practical functionality. A pragmatic stack also includes monitoring to detect stale metadata and mechanisms to reconcile conflicting definitions.
Practical role design and accountability
A centralized strategy succeeds when roles are clearly defined and empowered. Data stewards maintain business glossaries and certify datasets. Data owners accept accountability for access controls and retention policies. Metadata engineers automate ingestion and maintain mappings to source systems. Consumers provide feedback on usability and flag issues. Governance committees arbitrate disputes and approve cross-domain policies. Embedding metadata responsibilities into existing job descriptions helps institutionalize practices without creating siloed overhead. Incentives and recognition programs that reward quality documentation and timely certification encourage frontline teams to participate in the centralized ecosystem.
Operationalizing metadata workflows
Operational workflows bridge everyday data operations with governance objectives. Change management should start with small pilots that demonstrate value: a targeted set of critical datasets, a few business definitions, and measurable improvements in discovery time or incident resolution. Iterative rollouts refine ingestion templates, annotation guides, and certification gates. Automation plays a pivotal role: continuous harvesting of schema changes, scheduled quality checks, and notifications for consumers when critical datasets change. Workflows should also support exceptions and temporary overrides, with clear expiration dates and escalation paths. The aim is to reduce friction for data producers while increasing transparency for consumers, enabling velocity without chaos.
Measuring impact and iterating
Success metrics must align with governance objectives and business outcomes. Leading indicators include the percentage of critical datasets with certified metadata, time-to-discovery for analysts, and reduction in duplicate dataset creation. Lagging indicators map to compliance outcomes, such as audit readiness and the number of access violations. Regularly review metrics to inform roadmap decisions: which connectors to prioritize, where automation needs more intelligence, and what training or incentives are most effective. Periodic metadata audits help detect drift between technical schemas and business definitions. Continuous improvement cycles guarantee the metadata strategy adapts as the organization scales and new data paradigms emerge.
Scaling with federation and standards
As organizations grow, a hybrid pattern often emerges. Centralization can coexist with federated execution by establishing a canonical layer for cross-domain governance while permitting domain-specific metadata stores optimized for local needs. Standards and shared schemas function as the contract that ensures interoperability. Governance rules determine when federation is appropriate, how synchronization occurs, and which artifacts remain master in the central repository. This hybrid approach prevents the central system from becoming a bottleneck and leverages local expertise where domain context is essential.
Embedding metadata into culture and processes
Long-term value stems from treating metadata as an integral part of product delivery and operational workflows. Onboarding programs should include metadata training. Release pipelines must include metadata checks, and incident response playbooks should query lineage and ownership information as part of root cause analyses. Executive sponsorship is crucial to secure budget and remove organizational blockers. When metadata stewardship becomes routine rather than exceptional, the organization gains resilience: faster onboarding of new tools, more reliable analytics, and clearer accountability for data-driven decisions.
A centralized metadata strategy is not a one-time project but an ongoing capability that evolves as architecture and business needs change. By aligning technology, roles, workflows, and metrics, organizations can scale governance pragmatically and support the agility demanded by modern data consumers. Introducing a single authoritative registry such as a Data Catalog can catalyze this shift, providing the visibility and control necessary to govern data at enterprise scale while enabling teams to move quickly and confidently.





